Featured Participant of the CJDC Datafest: Avery Tamura
Margaret Haughney | July 31, 2023
In February, we hosted the Civil Justice Data Commons Datafest to allow researchers from all backgrounds and institutions to explore the civil court case data available from CJDC. Among the participants, we received a strong project submission titled “Judgment Amounts and Claim Amounts in Eviction Cases” from Avery Tamura.
Avery is a Master’s student in the Statistics department at Columbia University. With a strong academic background in statistical methods and techniques, Avery has also gained practical experience through numerous internships and projects. Currently, she works as a Data Analyst Intern at Lumen Technologies, providing data visualizations that aid in the maintenance and improvement of some of Lumen’s most crucial processes. We were excited to learn more about Avery’s experience and interest in civil justice research, and we have featured her interview below.
CJDC: Why did you choose to participate in Datafest?
AT: I first learned about this Datafest through the Statistics department at Columbia University. The main aspect that drew me to participate was the opportunity to contribute to a project for a social good. Through the initial Datafest information session, I saw how passionate the team was for increasing the collection of civil court data. I come from a family with a legal background, so I understand the importance of these smaller cases to real peoples’ lives. Coupled with my belief in the power of data, participating in the CJDC Datafest was an obvious choice.
CJDC: Tell us about your project. What problem did you want to solve and what did you do with the data?
 AT: The problem I wanted to solve was inequity in the amount awarded in these civil cases as part of the final judgment. My initial hypothesis was that individuals with the resources for legal counsel would receive larger judgments awarded to them if they won, compared to those who still won their case but did not have legal representation. Of course, there would be other potential aspects that could contribute to this divide.
AT: The problem I wanted to solve was inequity in the amount awarded in these civil cases as part of the final judgment. My initial hypothesis was that individuals with the resources for legal counsel would receive larger judgments awarded to them if they won, compared to those who still won their case but did not have legal representation. Of course, there would be other potential aspects that could contribute to this divide.
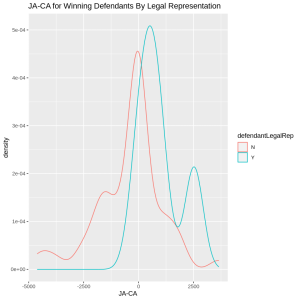
For each civil case in the dataset, I calculated what I call a “ja-ca” score which represents the monetary benefit for the winner of the civil case. I created the ja-ca scores by calculating the difference between the judgment amount awarded in the case and the initial claim amount made by the plaintiff. In the cases that ruled in favor of the plaintiff, the ja-ca score shows how much the plaintiff was awarded, relative to what they expected to receive. In cases that ruled in favor of the defendant, the ja-ca score shows how much the defendant was awarded, relative to the size and severity of the case since we would expect more severe cases to have a higher monetary demand from the plaintiff. In both cases, the ja-ca score gives an overall sense of whether the winner of the civil case got a judgment amount more than what was expected, about the same as what was expected, or less than what was expected.
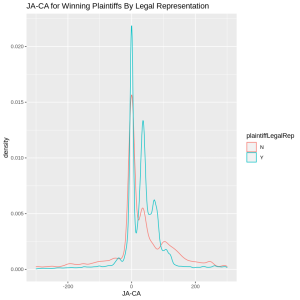 Then, I analyzed this ja-ca score across four different groups: plaintiffs who won their cases and had legal representation, plaintiffs who won their cases but had no legal representation, defendants who won their cases and had legal representation, and defendants who won their cases but had no legal representation. The findings showed that there were significant differences between these groups. Defendants who won their case and had legal representation typically got the highest judgment amounts, and defendants who won their case but had no legal representation typically got the lowest. Similarly, plaintiffs who won their case but had no legal representation got a lower judgment amount than plaintiffs who won their case and had legal representation.
Then, I analyzed this ja-ca score across four different groups: plaintiffs who won their cases and had legal representation, plaintiffs who won their cases but had no legal representation, defendants who won their cases and had legal representation, and defendants who won their cases but had no legal representation. The findings showed that there were significant differences between these groups. Defendants who won their case and had legal representation typically got the highest judgment amounts, and defendants who won their case but had no legal representation typically got the lowest. Similarly, plaintiffs who won their case but had no legal representation got a lower judgment amount than plaintiffs who won their case and had legal representation.
CJDC: How did you choose which datasets to use? Was this your first time using civil court case data?
AT: The dataset this study was based on was the first 100,000 cases from the “Maricopa County Arizona – Full Detail” dataset provided by the CJDC team at Georgetown University. I chose this subset largely for pragmatic limitations since my technology had difficulty handling any larger datasets, but also because the dataset for Maricopa County included much of the information related to judgment amounts and the context of who won the civil cases. This was my first time using civil court case data, but I’ve worked with fairly similar data throughout my career.
CJDC: What motivated you to focus on this topic?
AT: Winning cases can be expensive, and as a society, we should ensure that those who have won civil court cases should receive a fair amount of compensation, regardless of whether they had the resources for legal representation. Exploring discrepancies in monetary benefit between those who have legal representation and those who don’t brings attention to possible inequalities and encourages the exploration of possible solutions.
CJDC: What would you like to see happen with your idea/project next?
AT: I would like to see a more in-depth intersection between my analysis and an expert in this area. Expert input can allow us to cross-reference statistical findings with expectations from the field and to guide the study to align with pressing issues. In this study, I think an examination of what judgment amounts are and how they are decided and given would provide context on the implications of judgment amounts in civil cases.